Background
Classical software engineering (as we once knew it) is dead, and for good reason. The last true paradigm shift in programming was in 1972, when Dennis Ritchie released the C programming language. Everything since then has been optimizations and abstractions to make it easier to write and translate machine code.
And for a long time, this is how productivity in programming was measured: by the [time, space) efficiency, length and interpretability of your code.
We are now full swing in a new paradigm and we are likely not turning back to the days of writing raw [insert programming language].
John Carmack recently mentioned that soon enough the best tools for building will transition from hand coding to AI guiding, so you should focus more on building “product skills” and continue to use the best tools.
Software engineering will gradually morph into product engineering. Here are some ideas on what that will look like:
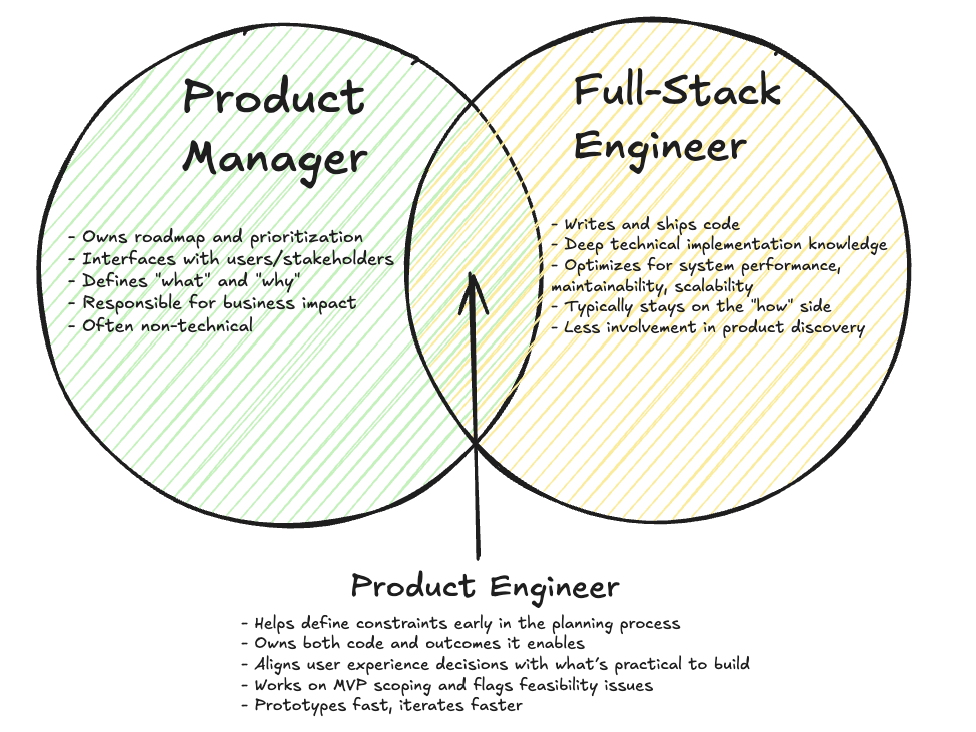
The Product Engineer
The product engineer is a mix of a product manager and full stack software engineer. These are programmers who will own the full product cycle and will live and die by their product.
They will be:
- AI-native: meaning they use LLMs as a foundational tool rather than as an add-on
- T-shaped: with deep engineering skills but broadly skilled across product, data and design
- deeply outcome oriented: owns KPIs like retention, activation, conversion etc.
- highly autonomous: Can go from idea → spec → design → deploy with little oversight
These PEs will form highly talented, lean teams where members are largely interchangeable. Rather than splitting work along technical expertise (like frontend, backend, or infrastructure) teams will organize around products and features. In this model, engineers aren’t siloed by stack; they’re aligned by outcomes. One PE might own onboarding, another payments, another notifications; each accountable for their feature end-to-end, from the UX to data layer. The structure shifts from “frontend/backend/infra teams” to “feature squads”, each with full-stack autonomy.
There are two sides to the product engineer: the product (pre-development) and the engineer (in/post-development).
The Product
The product half of the product engineer is responsible for: 1 2
- Product ideation: Involves identifying and detailing the core features, value proposition, and user demographics of a product.
- Mind-mapping: Drawing the graphical or pictorial representation of ideas or tasks emerging from a core central concept.
- Brainstorming: Independently writing down their ideas, passing them on to others for idea development, enhancement and sound boarding.
- Discovery: Involves exploring, researching, understanding customer needs, and identifying market opportunities to develop a product that aligns with business goals while providing value to users.
- Selection: Identifying which features and projects to prioritize, based on the product’s strategic direction, business objectives, customer needs, and market trends.
- Market analysis: The examination of the market within which the product will operate.
- User research: Process of investigating and understanding the needs, behaviours, and pain points of a user.
- Product design: UI/UX design, service design, interaction design, user testing.
These are classical product manager roles and they seem like a lot, but remember: the AI is on your side and you should work with it and not for it. AI right now is very good at regurgitation and not very good at forming novel ideas3. It is imperative that you maintain the vision of your product, and only use AI as a soundboard for iterative ideation. Given some broad vision, AI tools could help you iron out common kinks from similar projects it has already seen.
The Engineer
The other half of the product engineer equation is responsible for the execution of the now largely fleshed out project specification.
They will be responsible for 4 main facets:
- Software architecture: Making decisions on structural choices that would be costly to change once implemented.
- System design: Defining and developing systems.
- Front-end engineering: Implementation of visual designs and client facing functionality.
- Backend engineering: Implementation and optimization of business logic + database design.
I understand that the engineer iceberg goes deep and there are some major areas I have overlooked such as testing, observability and (ironically) AI integration, but for the vast majority of projects, advanced solutions in those areas are not as important as just building and shipping a SLC (Simple, Lovable, Complete) product.
Because coding LLMs work well in clearly definable, deterministic environments, engineering is where AI can do a lot more of the heavy lifting as compared to the product side.
Leveraging AI is still an emerging topic, and we’re still (for the most part) figuring it out, but here are some general pointers:
Planning
This is perhaps the most valuable action you can take in helping the AI help you. Giving the AI model an understanding of the project’s intent via well structured requirements is a great long term investment for the quality of code output from the model. 4
Rules allow you to provide your AI coder with system-level guidance; which it in turn uses as persistent, reusable context5. This improves output consistency. Cline has a good specification on how to structure effective rules.
You can define your rules with the following structure, or something to this effect:
# Project Guidelines
## Documentation Requirements
- Update relevant documentation in /docs when modifying features
- Keep README.md in sync with new capabilities
- Maintain changelog entries in CHANGELOG.md
## Architecture Decision Records
Create ADRs in /docs/adr for:
- Major dependency changes
- Architectural pattern changes
- New integration patterns
- Database schema changes
Follow template in /docs/adr/template.md
## Code Style & Patterns
- Generate API clients using OpenAPI Generator
- Use TypeScript axios template
- Place generated code in /src/generated
- Prefer composition over inheritance
- Use repository pattern for data access
- Follow error handling pattern in /src/utils/errors.ts
## Testing Standards
- Unit tests required for business logic
- Integration tests for API endpoints
- E2E tests for critical user flows
You can also auto-generate these on most coding IDEs i.e. /Generate Cursor Rules 6
Software Architecture
Software architecture is about the big-picture, high-leverage decisions: the kind that shape the skeleton of your codebase and are expensive to change later. These are decisions like:
- Choosing architectural patterns (e.g., monolith vs microservices, serverless vs containerized, that kind of thing)
- Dependency management and defining integration boundaries
- Enforcing modularity and separation of concerns
- Defining communication protocols (REST, GraphQL, gRPC, event buses, etc.)
- Scalability strategy, even if deferred e.g., do you anticipate horizontal scaling?
The role of AI in software architecture is nuanced. While LLMs are unlikely to invent better architectures than experienced engineers, they can add value by stress-testing assumptions. You can ask them to explore trade-offs between competing design patterns, generate system diagrams (e.g. via Mermaid.js), or draft architecture decision records. These are useful at an abstract level. However, architectural suggestions from AI should never be followed blindly. They need to be tempered by human judgment, contextual awareness, and deep domain expertise. This is one area of engineering that AI is unlikely to fully restructure anytime soon, making deep architectural expertise more valuable than ever.
System Design
System design involves defining and developing systems; and is where architecture gets grounded into reality. It’s about breaking down product features into services, data flows, state machines, and interfaces that are understandable, maintainable, and scalable.
A typical system design task includes: defining APIs and service boundaries, mapping out data models and how data flows between layers, thinking through error handling/failure recovery, modelling state transitions or asynchronous workflows and writing design docs and reviewing edge cases
I haven’t used it myself, but I think AI can be particularly strong here when used well. You can use LLMs to generate initial system designs based on a clear feature spec, simulate edge cases or concurrency issues, draft API interfaces, data schemas, and state machines or compare common system design patterns. I suspect the real power comes from interactive iteration where you share your initial sketch, and ask the AI to poke holes in it. Treat it like a junior engineer with endless curiosity and no ego.
Frontend engineering
Frontend engineering involves implementing visual designs and client-facing functionality. In my experience, AI performs quite well here, especially with JavaScript frameworks like React, (because the most widely used framework for the most popular frontend language). Its ubiquity means there’s extensive documentation and well-established patterns, which are all very good for the AIs.
One useful technique to get your AI assistant up to speed is providing a design framework that matches all your brand guidelines (fonts, colours) before letting it write a single line of code. I’ve found that feeding your AI editor a couple screenshots of your brand guidelines and having it define, in code, all these guidelines has been a major boost. These brand guidelines could define your fonts, colour palette, heading sizes, line and letter spacing, and other repeatable visual components. It’s also helpful to specify how these components should behave responsively across different screen sizes. From there, the AI can define these elements in code (e.g., as a Tailwind config, CSS variables), creating a consistent visual foundation and improving its ability to generate brand-aligned UI code going forward. There are Figma-to-code tools out there like Tempo but I haven’t tested them out. So far, I’ve tried just copy-pasting screenshots of designs and deign specification documents and have had moderate success with it.
Backend Engineering
Backend engineering involves Implementation and optimization of business logic + database design. I find that AI tools are very good at implementing business logic & core feature functionality, designing databases and building APIs. Of course, the tasks have to be well scoped: D&D (definable and deterministic). This is a common theme in this engineering portion. Some useful techniques that have helped me personally:
- Import documentation: AI IDEs allow you to import documentation right into the workspace, which reduces hallucinations
- Use workspaces: All VS Code forks allow you to add folders to your workspaces via
File > Add Folder to workspaces. They provide more context and are especially important for projects with separate frontend and backend codebases.
General Tips for the Product Engineer
Always work at the frontier
Keep up to the date with the latest models available because:
- The context window size increases; which allows models to “understand” larger projects
- The models improve in performance: newer models reason better, hallucinate less and are typically more reliable
Use thinking mode
I’ve found that the quality of a model’s answers increases dramatically with thinking mode on. If given the option to trigger thinking mode on, always have it on. If not, one hack is to include the word “ultrathink” somewhere in your prompt.
Be hyper-specific
Give the exact goal you’re trying to accomplish, include any constraints or design decisions that matter and provide relevant code snippets, file paths and component names. This is a good prompt:
Add analytics tracking to the
/src/pages/SignUp.tsxform so that when a user clicks ‘Submit’, we fire asign_up_startedevent using thetrackEvent()function from/src/lib/analytics.ts. Make sure to debounce the event, and include the user’s email domain (e.g., ‘gmail.com’) as a property.
Provide visual context
Especially when working on frontend tasks. Current coding LLMs understand images so attaching screenshots of designs and error messages caused by bugs can help the model debug and fix stuff faster.
Work in small iterations
Start by having the AI develop the basic functionality, and then work on polishing it via improvements. (Again!) Break up your prompts into multiple clear, definable instructions.
Stay curious
The internet is littered with tips like these and hanging out in the right corners of the internet will keep you exposed to what the smartest people are taking advantage of.
Closing thoughts
I still think there are skills that won’t be replaced any time soon, and some will become even more valuable as a result of the AI revolution.
- Having a good command on CLI tools (like git) is increasingly valuable. Git is the most efficient way to keep a paper trail of all the working versions of your code, and given how unreliable AI-generated output is, it is important to have the option to revert your progress and regroup.
- Having your engineering fundamentals in check: We have to think about how to deal with technical debt. It is not always obvious to the AI to compartmentalize/modularize the code so upholding good style fundamentals like naming things well and writing DRY modular code will become more valuable. However, I’m not sure how this will hold going into the future as more and more code is written by AI…
- Being a strong communicator (in writing and speech) is also proving to be more valuable over time. Clarity is leverage. AI models, in particular, don’t infer intent the way humans do. They follow your instructions exactly, including your blind spots. The better you are at articulating what you want, the better your AI assistant (and your team) can deliver it. Writing good specs, clear prompt instructions, well-structured documentation; all of it adds up to faster, higher-quality output with less rework.
This also spills over into just basic big corp office politics. Technical work is very well suited to be increasingly eaten up by AI because of it’s D&D (definable and deterministic) property. So as more technical work is outsourced to the AIs, the value of someone who can manage the AIs to work faster, be more productive and present polished results to shareholders increases. In large organizations, the production process is often invisible to shareholders and upper management. They don’t see how the work was done, just what was delivered. So as AI makes execution cheaper and more commoditized, the perceived value of presentation, packaging, and strategic delivery rises. People who can align AI output with business goals, communicate clearly, and drive visible outcomes will increasingly hold power and not necessarily those doing the raw technical implementation. I understand that this may already be the case, but the scales will tip more in the manager’s favour.
Introducing the role of the PE will beckon changes in organizational structures going forward. This will apply more to new and emerging companies (startups), but as these startups scale and as AIs become more autonomous, we might start to see novel team topologies emerge. Instead of the traditional PM–designer–engineer triangle, we could see leaner pods led by product engineers who act as fullstack builders with product sense, paired with AI copilots that augment them across the stack… but more on that in a future blog post.
References
David Crawshaw on agents
The one person framework.
Sahil Lavingia on PMing with o1 pro, v0, and DeepSeek-R1
Chris Raroque YouTube
Death of the Software Engineer (and the Rise of the Product Engineer)